Lektion 06
Ziele
- Lorenzkurve kennen, «herstellen» und interpretieren können.
- Gini-Koeffizient kennen und interpretieren können.
- Erste Ideen eines eigenen Projekts generieren
Aufträge
- Theorie Lorenzkurve lesen
- Beispiel mit Hilfe der Excel-Datei zur Lorenzkurve erstellen, die maximal ungleich verteilt sind resp. gleich verteilt sind.
- Wahlweise:
- Eigenen R Code schreiben
- Gini und Lorenzkurve weiter vertiefen mit
- Artikel zur Lorenzkurve lesen und Seiten 14-16 in Lohnreport der Stadt Zürich betrachten. Überrascht die Grafik? Wie sähe die Verteilung in der Stadt St. Gallen aus? Unglücklicherweise sind die gleichen Daten weder für St. Gallen noch jährlich verfügbar.
- Auf der OECD-Webseite können verschiedene Merkmale zur Einkommensverteilung über die Zeit (Schiebregler unten rechts) für verschiedene Länder betrachtet werden. Suche dir ein Land, dessen Gini-Koeffizient sich in den letzten Jahren stark verändert hat. Was könnte eine Geschichte dazu sein?
- Überlege dir alternative Masse, um Konzentration resp. Ungleichverteilung (im Einkommenskontext) zu messen.
- Besprich mit deinem/r Nachbar:in Ideen für eine eigene Projekte, welche untersucht werden könnte und halte diese hier fest.
Theorie
Auf Grund der Lorenzkurve kann ausgesagt werden, wie stark die Merkmale (resp. deren Ausprägung) konzentriert sind (ein Konzentrationsmass). Das klassische Beispiel dabei ist die Einkommenverteilung. Die Frage, die dabei gestellt, resp. beantwortet wird, ist “Wie viel Prozent der Leute (Köpfe) verdienen wie viel Prozent des Gesamteinkommens?»
| Einkommen | Anzahl Personen | Kumululierte relative Anzahl | Einkommenssumme | Kumululierte relative Einkommenssumme |
|---|---|---|---|---|
| 2317 | 10 | 0.20 | 23'170 | 0.17 |
| 2552 | 11 | 0.42 | 28'072 | 0.37 |
| 2787 | 14 | 0.70 | 39'018 | 0.65 |
| 3022 | 8 | 0.86 | 24'176 | 0.83 |
| 3257 | 3 | 0.92 | 9'771 | 0.90 |
| 3492 | 4 | 1.00 | 13'968 | 1.00 |
| Total | 50 | 138'175 | ||
Zeichnet man nun die Punkte $(\text{Kumulierte relative Anzahl},\text{Kumulierte relative Einkommenssumme})=(x,y)$ und verbindet diese, erhält man die Lorenzkurve:

Zwischenfrage: Wo würden die Punkte liegen, wenn alle gleich viel verdienen würden?
Beispiele
Als Mass der Ungleichverteilung verwendet nun die Fläche, welche die Lorenzkurve mit der Winkelhalbierenden einschliesst. Diese Fläche nennt man auch Gini–Koeffizient

Als Beispiel für die Lorenzkurve wiederum die 5 BMW Modelle und ihre Preise. Achtung: Es handelt sich dabei nicht um ein Einkommen!
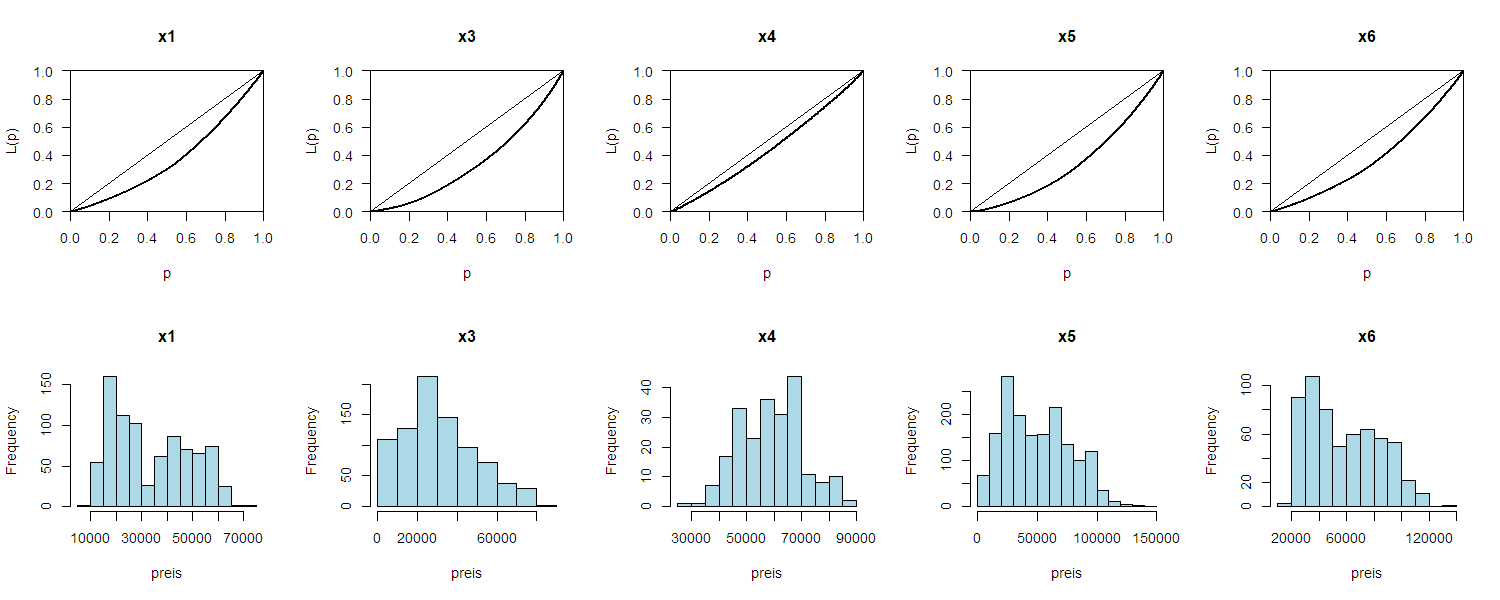
Die Lorenzkurve macht im Allgemeinen nur Sinn für Merkmale, mit positiven Werten (Preis, Einkommen, etc.)
Umsetzung in R
In R kann die Lorenzkurve ebenfalls umgesetzt werden. Wichtig sind dabei folgende Funktionen
sortcumsumundsumlengthplotmitplot(xwerte,ywerte)kannst du einen Scatterplot mit erstellen.
Versuche mit den Funktionen oben, die richtigen $x$- und $y$-Werte zu erstellen und diese an anschliessend zu zeichnen.
Versuche zuerst mit «Dummy»-Date, dann kannst du dich um die Funktion kümmern, ohne die Daten einzulesen.
dummydata <- c(70, 40, 70, 50, 30, 80, 90, 90, 40, 80, 40, 20, 40, 10, 40, 60, 100, 30, 30, 70, 50, 70, 50, 40, 70, 60, 90, 50, 90) xwerte <- ... ywerte <- ... plot(xwerte,ywerte)
Lektion 05
Ziele
- Boxplot erstellen und interpretieren
- Lage und Skalenmasse auf Grund Boxplot und Kennzahlen interpretieren
Aufträge
- Boxplot
- Theorie Boxplot unten lesen.
- Einen Boxplot von Hand der Daten 9, 6, 7, 7, 3, 9, 10, 1, 8, 7, 9, 9, 8, 10, 5, 10, 10, 9, 10, 8 erstellen.
- Einen Boxplot von Hand (mit Hilfe R
median,quantileetc.) der Preise von einem BMW Modell (X1 bis X5) erstellen. - Einen Boxplot mit R (automatisch mit z.B.
boxplot(cardata$preise)) erstellen. Boxplots können in R auch entlang verschiedener nominaler Variablen erstellt werden: Dazu muss einfach eine Tilde~eingefügt werden, z.B.boxplot(cardata$preis~cardata$model). - Die BMW Boxplots den BMW Histogrammen zuordnen (auf Papier vorne)
- Die BMW Mittelwerte, Standardabweichungen, IQA, Median und $Q_{30\%}$ den Histogrammen und Boxplots auf zuordnen.
- Anwendungen des Boxplots
- Abschnitt unten zu ”Anwendungen Boxplot“ durchgehen
- Ein Beispiel konstruieren, bei dem Median grösser als Mittelwert ist.
- Eine erhobene Grösse ausdenken, bei der Median (oder ein anderes Quantil) mehr interessiert als der Mittelwert und umgekehrt.
Boxplot

Ein Boxplot besteht aus einer Box, welche durch das erste und dritte Quartil ($Q_{25\%}$ und $Q_{75\%}$) begrenzt ist. Damit liegen $50\%$ der Daten in der Box. Der mittige Strich ist der Median ($q_{50\%}$), die Whiskers (Antennen oder Schnäuze) sind $w_1=Q_{50\%}-1.5\cdot IQA$ und $w_2=Q_{50\%}+1.5\cdot IQA$. $w_1$ und $w_2$ sind dabei zum Teil auch durch den grössten (resp. kleinsten für $w_1$) Wert eines Datenpunktes ersetzt, welcher gerade noch kleiner (resp. grösser für $w_1$) ist als $w_2$. Die Whiskers sind dann nicht symmetrisch. Die Punkte, die ausserhalb der Whiskers liegen, nennt man Outlier oder Ausreisser. Man kann zeigen, dass bei normalverteilten Daten, ca. $95\%$ der Beobachtungen innerhalb der beiden Whiskers zu liegen kommen.
# x1
- Mittelwert: 34155.8
- IQA: 27625
- $Q_{30\%}$: 21900
- Median: 29900
- Standardabweichung: 15200.1
# x3
- Mittelwert: 32018.2
- IQA: 25225
- $Q_{30\%}$: 21500
- Median: 28900
- Standardabweichung: 18084.7
# x4
- Mittelwert: 59603
- IQA: 17175
- $Q_{30\%}$: 52675
- Median: 59900
- Standardabweichung: 11709.4
# x5
- Mittelwert: 51018.6
- IQA: 42975.2
- $Q_{30\%}$: 29900
- Median: 47949.5
- Standardabweichung: 27569.1
# x6
- Mittelwert: 59023.7
- IQA: 43977.5
- $Q_{30\%}$: 38909
- Median: 56400
- Standardabweichung: 25544.2
Lösungen: Boxplot der Preise nach Modell


Anwendungen Boxplot
Löhne in der Stadt Zürich
- Lohnreport der Stadt Zürich herunterladen.
- Insb. Seiten 14 bis 15: Überrascht diese Verteilung (Histogramm)?
- Welche Grafiken / Methoden sind aus dem Freifach bekannt?
- Gibt es irgeneine Graphik im Lohnreport, welche nicht klar ist?
- Die Medienmitteilug dazu hatte als Titel “Gute Ausbildung lohnt sich”. Teilst du diese Meinung nach Studium des Lohnreports?
- Im darauffolgenden Jahr wurde noch die Löhne von Männern und Frauen untersucht. Was beobachtest du?
- Wie würde der Lohnreport der Stadt St. Gallen aussehen?
Lektion 04
Ziele
- Jede/r kann ein Histogramm erklären.
- Jede/r kann Mittelwert, Modus, Median und beliebige Quantile von Hand und mit Excel/R ausrechnen (Lagemasse)
- Jede/r kann Varianz, Standardabweichung, IQA ausrechnen von Hand und mit Excel/R (Skalenmasse)
Auftrag
- Definitionen auf Unterlagen vom letzten Mal falls nötig nachlesen und mit Begriffen unten ergänzen.
- Definitionen aus der heutigen durcharbeiten und nachvollziehen.
- Berechne für die genannten Grössen für
-2.9, 25.4, -12.3, -38.5, 4.2, 23.7, -0.4, 1.5, -23.3, 21.von Hand und mit Excel - Berechne für verschiedene BMW Modelle ein Histogram und notiere Mittelwert, Median, Standardabweichung und IQA darunter. Eine mögliche Vorgehensweise dabei wäre
- R:
- Variante A: Die gewünschten Modelle mit einem Vergleich
x5 ← cardata$model== “x5”speichern, dieser dann als Index verwendencardata$preis[x5]und damit die Grösse Mittelwert, Median, etc. (s.u.) berechnen - Variante B: Wiederum mit
ddplyundsumariseund den entsprechenden Funktionen (s.u.) arbeiten.
- Excel:
- Alle Preise in ein neues Tabellenblatt kopieren
- Jeweils in den ersten Zeilen die Grössen für die darunterliegenden Werte ausrechnen und dann Formeln nach rechts ziehen.
- Zusatzauftrag:
- Excel In Excel können sogenannte normalverteilte Zufallsvariablen mit folgendem «Trick» simuliert werden
=NORM.INV(ZUFALLSZAHL();0;1). Damit erhält man eine Zufallszahl. Simuliere eine Spalte mit z.B. 200 normalverteilten Zufallszahlen und zeige dann ein Histogramm an. Verändere dann die Zufallszahlen in dem du verschieden Mittelwerte $m$ und Standardabweichenungen $s$ verwendest. Du kannst dazu einfach die Werte in der Formel einsetzen:=NORM.INV(ZUFALLSZAHL();m;s). Stelle sicher, dass beim Histogramm die Achsen identisch bleiben (Rechtsklick auf Achse) - R Mit
rnorm(n,m,s)können $n$ sogenanntne normalverteilte Zufallsvariablen simuliert werden. Simuliere einige Histogramme mit verschiedenen Mittelwertenmund Standardabweichungens. Die Bilder der Histogramme sollen dann den Werten vonmundszugeordnet werden. Stelle sicher, dass die beim Histogramm die Achsen identisch bleiben. Das geht überhist(rnorm(…),xlim=c(min,max))wobeiminundmaxdie extremen Werte der Achse sind. - Schau dir die folgende Excel Datei an: Diese “simuliert” ein Histogramm nach deinen Vorgaben.
Definitionen Lektion 04
Quantil
Ein Quantil gibt den dem Prozentrang zugehörigen Wert der Verteilung wieder. Der Median ist z.B. das 50% Quantil. Das 25%-Quantil z.B. ist der Wert, für welchen gilt, dass 25% der Werte kleiner und 75% der Werte grösser sind. Mathematisch kann man das wie folgt festhalten:
Möchte man das Quantil $\alpha=35\%=0.35$ von den $n=15$ Daten 10.6, 16.9, -27.3, 9.6, 18.1, -6.4, 34.4, 42.7, -3.6, 5, -3.2,
11.1, 46.1, 19.4, 2.4 berechnen, so muss man diese zuerst aufsteigend sortieren: -27.3, -6.4, -3.6, -3.2, 2.4, 5, 9.6, 10.6, 11.1, 16.9, 18.1,
19.4, 34.4, 42.7, 46.1. Die sortierten Werte werden mit $x_{(1)},x_{(2)},\ldots,x_{(n)}$ bezeichnet. Man sucht dann diesen Wert so, dass der gefundene Wert dem geforderten Prozentrang von $\alpha=0.35$ am nächsten kommt.
Genauer: Sei $K=\lfloor\alpha\cdot n\rfloor+1$ wobei $\lfloor\cdot\rfloor$ auf die nächste ganze Zahl abrundet. Für uns ist also $K=\lfloor0.35\cdot 15\rfloor+1=\lfloor5.25\rfloor+1=5+1=6$. Wir nehmen also den 6. Wert: Damit ist $Q_{0.35}=x_{(6)}=5$
Ist aber $\alpha\cdot n$ eine natürliche Zahl so, so nehmen wir wegen des Abrundens den mittleren der beiden Werte $x_{(K-1)}$ und $x_{(K)}$: Für $\alpha=0.3$ ist $K=3+1=4$ und damit $Q_{0.2}=\frac12((-3.6)+(-3.2))=-3.4$. $$Q_\alpha=\begin{cases}x_{(K)}\text{ wenn $\alpha\cdot n$ nicht ganzzahlig}\\\frac12\left(x_{(K)}+x_{(K-1)}\right)\text{ wenn $\alpha\cdot n$ ganzzahlig}\end{cases}$$
Quartile
Quartile sind die $25\%$, $50\%$ und $75\%$ Quantile einer Verteilung. Für das erste Quartil gilt also, dass $25\%$ der Beobachtungen kleiner sind, $75\%$ der Beobachtungen sind grösser.
Bei der Berechnung der Quantile kommen bei unterschiedlichen Softwarelösungen unterschiedliche Methoden zum Einsatz. Das heisst, u.U. stimmen die Quantile zweier unterschiedlichen Softwarelösungen nicht überein.
Interquartilsabstand (IQA)
Der Interquartilsabstand ist ein Mass für die Skala einer Verteilung. Wie weit sind das erste und dritte Quartil auseinander: $\text{IQA}=Q_{0.75}-Q_{0.25}$.
In Buch R-Reader:
- Kapitel 2 insb. Kapitel 2.2.1 Dataframes lesen
- Kapitel 4 insb. Anfang
Lektion 03
Ziele
- Unterlagen durcharbeiten.
- Der Begriff des Zufalls ist intuitiv bekannt bei Experimenten (Würfeln) wie auch erhobenen Daten (Autopreise): In Alltagssprache Zufall beschreiben.
- Jede/r kann ein Histogramm erstellen und interpretieren.
- Jede/r kann mit R Zufallszahlen (Würfel) erzeugen.
Aufträge:
- Eile-mit-Weile Auftrag ausführen
- Zuerst manuell mit Strichliste und Würfeln.
- Nachher mit R Simulieren. Hilfreicher Funktionen sind
sample(oder, wer es gerne manuell magrunif,ceiling).
- Histogramm mit R erstellen:
hist(…)erstellt ein Histogramm.- Histogramm der Fahrzeugpreise (z.B. alle X1) erstellen und diese vergleichen.
R Code Simulation Eile-mit-Weile
In R kann man auch Würfel (und vieles mehr) simulieren, mit sample wird eine Zahl aus einem Zahlenbereich zufällig ausgewählt. So könnte z.B. mit sample(1:45, 6, replace=FALSE) das Ziehen von 6 Zahlen beim Schweizer Zahlenlotto simuliert werden. 1:45 ist die Menge, aus welcher zufällig gezogen wird, 6 sind die Anzahl Elemente und replace=FALSE besagt, dass die Kugeln/Elemente nicht zurückgelegt werden vor dem nächsten Ziehen.
Mit replicate(n,{…}) wird alles n mal wiederholt, was zwischen den geschweiften Klammern steht.
- Level 1 (ohne
replicate)- Würfle 1 mal mit R
- Würfle 100 mal mit R
- Würfle 1000 mal mit R
- Berechne die durchschnittliche Anzahl Sechsen bei allen Würfen oben. Du kannst dabei deine Resultate, welche du oben erhalten hast, vergleichen, das heisst,
res==6(resist dabei dein Resultat, also der Vektor, welche alle Würfe enthält). Dies ergibt einen Vektor mit lauterTRUEundFALSE. Mitsumodermeankannst du die Summe resp. den Durchschnitt berechnen.
- Level 2 (mit
replicate)- Überprüfe, wie oft du eine Summe von 12 mit zwei Würfeln, das heisst, zwei Sechsen, hast. Verwende wieder
replicateundsample. Du kannstsumundmeanauch innerhalb vonreplicateverwenden
- Level 3
- Schreibe eine Funktion, welche Eile mit Weile würfeln simuliert.
- Tipps:
sample(1:6,3,replace=T)wählt aus den Zahlen 1 bis 6 genau 3 auswhile(bedingung){ … }der Code in den Klammer wird ausgeführt, solangebedingungwahr ist. Die Schleife kann abgebrochen werden mitbreak.- Idee: Bedingung so wählen, dass weitergewürfelt wird, wenn eine gewürfelt worden ist $6$ ist.
replicate(n,…)wiederholt den Code … $n$ mal und hat die Rückgabewerte des aufgerufenen Codes als Liste resp. Vektor. z.B.replicate(10,sample(1:4,1))
Lösungen
Level 1
Level 2
Level 3
Histogramm Eile mit Weile bei 1'000'000 Würfeln

Lektion 02
Ziele
- Jede:r kann mit Pivot-Tabellen (in R:
plyr) einfache Analysen durchführen
Aufträge
- Abschliessen der Aufträge von letzter Woche.
- Schaut euch die Einführung Pivot-Tabellen unten an.
- Analysiert mittels Pivot-Tabellen folgende Fragen:
- Mittlerer Verkaufspreis aller weissen Autos berechnen
- Anzahl grüne Autos berechnen
- Welches Modell ist am teuersten?
- Welche Farbe oder Energieeffizienz ist am günstigsten? Ist das für alle Modelle und Farben oder Energieeffizienz identisch?
- Was ist der mittlere Preis aller Autos zwischen 0 und 20'000 Kilometern, 20'000 und 40'000 Kilometern?
- Verwende wiederum Pivot-Tabellen
- Erstelle zuerst eine Spalte in welcher du mit Runden (
=ABRUNDEN(xxx;stellen), in Rfloor(xxx)) die Kilometer 0, 20000, 40000,etc. angibst.
- Führe die gleiche Analyse für alle Modelle durch. Für alle Farben.
- Gibt es andere Zusammenhänge? Verbrauch? Zylinder?
Einführungsvideos
- ddplystattpivot.R
setwd("Pfad zum Arbeitsverzeichnis angeben") cardata <- read.table("bmw_data.csv",header = T,sep=";") # install.packages("plyr") # installiert Paket library(plyr) # Daten laden cardata <- read.csv2("bmw_data.csv") library(plyr) # Zusatzpaket 'plyr' laden (vorgänig mit install.packages("plyr") installieren) head(cardata) # Erste Zeilen anzeigen ?ddply # Hilfe zu ddply ddply(cardata, .(model), summarise, preis = mean(preis)) # Mittelwert des Preises nach Modell anzeigen ddply(cardata, .(model), summarise, preis = median(preis)) # Median des Preises nach Modell anzeigen ddply(cardata, .(model, zylinder), summarise, preis = mean(preis)) # Mittelwert des Preises nach Modell und Anzahl Zylinder anzeigen
Lektion 01
Ziele
Ziele der Lektion:
- Einführung Freifach
- Unterlagen kennenlernen
- Geräte und Tools kennenlernen
- Erste Berechnungen anstellen
- R Dokumentation Seiten 1-13 lesen und Beispiel-Code durcharbeiten
Auftrag
- Einführungsvideo schauen.
- Dossier erstellen:
- Word-Datei, One-Note Datei, Papier, o.ä.
- Formatierung anlegen
- R installieren
- R installieren R download
- RStudio isntallieren R Studio
- Spielen mit Daten:
- Mittlerer Verkaufspreis (Durchschnitt) aller Autos berechnen
- Mittlerer Verkaufspreis aller weissen Autos berechnen
- Anzahl blaue Autos berechnen
- Welches Modell ist am teuersten?
- Welche Farbe oder Energieeffizienz ist am günstigsten? Ist das für alle Modelle und Farben oder Energieeffizienz identisch?
- | intro.R
setwd("C:/Users/Simon.Knaus/Dropbox/git/ffstat") #Arbeitsverzeichnis bestimmen cardata <- read.table("cardata.csv",sep=";",header=TRUE) #Daten einlesen als Dataframe head(cardata) # Erste Zeilen (6) anzeigen summary(cardata) # Zusammenfassung anzeigen mean(cardata$preis) # Mittelwert des Preises anzeigen unique(cardata$model) #Alle Modelle nur einzeln (einmalig) anzeigen str(cardata) #Struktur des Dataframes anzeigen cardata[2,1] #2 Zeile, erste Spalte cardata[cardata$model=="x1", "preis"] #Model soll 'x1' sein, da die 'Preis'-Spalte mean(cardata[2:4,2]) #Mittelwert der 2. bis 4. Zeile der 2. Spalte
Begriffe
Begriffe, die festzuhalten sind:
| Begriff | Kurzbeschrieb | Excel | R | |
|---|---|---|---|---|
| Mittelwert | Arithmetisches Mittel ($\mu$). Man schreibt auch $\bar x$. | MITTELWERT() | mean() | |
| Anzahl | Anzahl | ANZAHL() | length() | |
| Merkmal | Eigenschaften eines Datenpunkts (z.B. Türen, Farbe etc.) | |||
| Merkmalsausprägung und -typen | Nominal (Farbe), Ordinal (Modell: X1 bis X6), Kardinal (z.B. Kilometer, Preis) | |||
| Absolute und relative Häufigkeit von $x$ | Die absolute Häufigkeit entsprichen dem insgesamten Vorkommen, die relative Häufigkeit ist das Vorkommen in Prozent, d.h., die absolute Anzahl dividiert durch die Gesamtanzahl | ANZAHL() oder SUMMEWENN() | ||
| Histogramm | Illustration von Daten. Die Säulenfläche ist proportional zur relativen Häufigkeit | |||
| Varianz | Die mittlere quadratische Abweichung, i.e. $\sigma^2=\frac1{n-1}\sum_{i=1}^n (x_i-\bar x)^2$ | VARIANZA() | var() | |
| Standardabweichung | Wurzel der mittleren quadratischen Abweichung $\sigma=\sqrt{\frac1{n-1}\sum_{i=1}^n (x_i-\bar x)^2}$ | STABWA() | sd() | |
| Median | Wert der mittig in der Verteilung aller sortierten Werte ist, resp. zum 50% Prozentrang gehöriger Wert | MEDIAN() | median() | |
| Modus | Der häufigste (die häufigsten) Wert(e) | MODUS.EINF() | Benutzerdefinierte Funktion modes(…) | |
| $\alpha$-Quantil | Zum Prozentrang $\alpha$ gehöriger Wert | QUANTIL.INKL() | quantile(,type=2) | |
| IQA | Interquartilsabstand. Differenz des 1. und 3. Quartils | QUANTIL.INKL(…;.75)-QUANTIL.INKL(…;.25) | IQR()) |
|